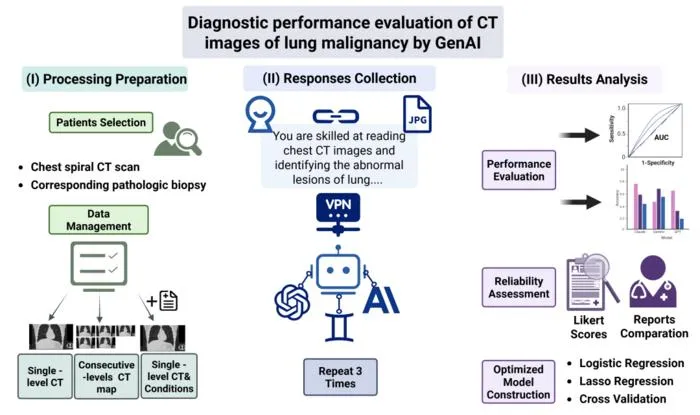
A new study evaluates the diagnostic accuracy of three leading generative multimodal AI models in interpreting CT images for lung cancer detection.
Key Details
- 1Three models compared: Gemini-pro-vision (Google), Claude-3-opus (Anthropic), and GPT-4-turbo (OpenAI).
- 2On 184 malignant lung cases, Gemini achieved highest single-image accuracy (>90%), followed by Claude-3-opus, GPT lowest (65.2%).
- 3Gemini's performance dropped to 58.5% with continuous CT slices, indicating challenges with spatial reasoning in imaging.
- 4Simplified text prompts improved diagnostic AUCs: Gemini (0.76), GPT (0.73), and Claude (0.69).
- 5Claude-3-opus showed superior consistency and lower variation in lesion feature analysis.
- 6External validation with TCGA and MIDRC datasets supported findings, especially with simplified prompt strategies.
Why It Matters
This benchmark provides essential insight into the current capabilities and limitations of leading multimodal LLMs for radiological image analysis. Understanding model strengths, weaknesses, and prompt engineering strategies will guide their optimal integration into clinical workflows.

Source
EurekAlert
Related News

•EurekAlert
AI Accelerates Radiopharmaceuticals, Boosts Personalized Dosimetry in Cancer
Machine learning is driving advancements in radiopharmaceutical drug discovery and optimizing patient-specific dosimetry for precision cancer therapy.

•EurekAlert
Physicians Overly Trust Erroneous AI, Ignore Contradictory Evidence
Physicians tend to trust incorrect AI advice, even when evidence contradicts it, suggesting risks in clinical decision-making with AI tools.

•EurekAlert
Concerns Raised Over Unverified Datasets in AI Health Prediction Models
A new study finds widely used AI health prediction models are built on datasets with unverifiable origins, raising safety and validity concerns.